
The Saavn music catalogue contains 40 million songs, spanning over a hundred different Indian languages. These songs have names containing Indian words but the app stores and displays these names in Roman script (i.e. English). Search over such a multilingual and heterogeneous catalogue is a mammoth task which brings us face-to-face with a number of challenges, one of which is Phonetics. Phonetics is the understanding of sounds-like spelling variations.
We have a song called “Zinda” (meaning ‘alive’) in our catalogue. Users frequently search for it with the query “Jinda”
Recognising that both these spellings represent the same word, and that they can be used interchangeably by a user, is what constitutes the problem of phonetics. Let us look at how we are tackling this challenge head-on at Saavn.
Phonetic Errors are not Spelling Errors
Most search engines handle misspellings using a spell correction module which typically builds a dictionary of correct tokens from the searchable corpus, corrects misspelled tokens to correct tokens using a lexical distance metric such as edit distance, and picks the best correction using the context in which the misspelled token occurs.
So why can’t a conventional spell correction framework handle Saavn’s phonetic errors as well? How are the phonetic errors we see in our queries so different from typos?
- Firstly, there is no concept of correct spelling. Since most Indian song titles contain non-native words written in the Roman script, the same word is spelt differently in different songs. This means there is no concept of a dictionary in our case. No reference list of correct words that we can correct against.
We have a Hindi song called Guzarish (meaning ‘wish’) in our catalogue. We also have a Hindi album called Guzaarish (double ‘a’). Users sometimes search for both these with the query ‘Gujarish’ (‘j’ instead of ‘z’)
- Secondly, there is no context. Around 50% of our queries contain just a single token or a pair of tokens giving us little to no context. Making it harder to guess the correct intention of the user.
Looking at a query ‘layla’ it is possible that a user is looking for the English song by Eric Clapton called Layla but it is also possible that he is in progress of typing a phonetically similar query for the much more popular Hindi song Laila main Laila.
- Which brings us to our third point – at the query end, it’s not easy to classify language. Saavn search is multi-lingual. We serve results across dozens of languages for the same search query. Thus, given a query, it is non-trivial to predict its language.
Phonetically spelling the Hindi or Bengali word ‘amar’ (meaning ‘immortal’) as ‘amor’ would turn it into a perfectly spelt spanish word ‘amor’ (meaning ‘love’), it’s not straightforward to judge what the user intended.
- Finally, phonetic errors differ from one language to another. Pronunciation rules of Tamil or Gujarati are very different from the rules of Hindi and even more so from the rules of English. A phonetic error very likely with a Gujarati word could be nearly impossible with an English word.
In an English title the token ‘tame’ would be pronounced like “game” and so it could probably be phonetically spelt as ‘taime’. But in Gujarati the token ‘tame’ (meaning ‘you’) is pronounced “ta-may” and so it could be phonetically misspelled as ‘tamay’ but never as ‘taime’
Goals of a Phonetics Framework
These insights quickly taught us that we need to design a different framework altogether to handle phonetic matching. Such a framework would need to serve the following goals.
- One size won’t fit all. The rules of pronunciation differ vastly between one language and another. Hence our framework will have to account for the linguistic differences of each Indian language separately while handling phonetics.
In Tamil, users often intermix ‘g’ with ‘k’ (The reason for this is in the native tamil alphabet, the letter for g and k sounds is the same, native speakers know when to pronounce what) i.e. they may query ‘thankachi’ for a song ‘thangachi thangachi’ (meaning ‘little sister’).
This is a phonetic error almost impossible in Hindi. A language agnostic approach would end up assuming the Hindi words ‘kala’ (meaning ‘black’) and ‘gala’ (meaning ‘neck’) to be phonetic variants of each other. Hence the rules that work for Tamil won’t work as well for Hindi and vice versa.
- Processing must occur at the indexing side. Not only are we armed with the knowledge of language of the song title at the indexing end, but we would also be removing any burden of processing at query time.
- We wish to match as many phonetic variations of a token as possible but also give preference to the exact term whenever we don’t have a lot of context information to go by.
- The framework must have high precision. Only true phonetic variations must be matched, or else we risk topic drift in the results.
- The framework must also have high recall, covering as many phonetic variations of a token as possible.
- While the framework may be developed for a handful of important Indian languages now, it should be extensible to other languages going forward.
Designing the Framework
The core of our phonetics framework is a distance metric quantifying how phonetically similar two tokens are. We call this metric Indi-Editex, (an extension of Editex developed for English phonetics matching). Broadly speaking Indi-Editex has the following features:
- We define edit penalties for substitutions, inserts and deletes of characters based on how phonetically similar they are. Similar sounding characters such as ‘v’ and ‘w’ have low edit penalties, different sounding characters have high edit penalties.
- Edit penalties are defined not just for single character edits but also for character groups such as ‘f’ and ‘ph’ substitutions. This models the concept of ‘syllable’ or a phonetic unit as closely as possible.
- Edit penalties take into account context such as whether the character group occurs at the start or end of a word, after a vowel or somewhere else.
E.g. In Hindi ‘ksh’ is interchangeable with ‘sh’ when at the starting of the word but not otherwise. Hence ‘kshitij’ (meaning ‘horizon’) could be written as ‘shitij’, but ‘lakshya’ (meaning ‘goal’) cannot be written as ‘lashya’
- Edit penalties are different for different languages.
In Hindi ‘t’ and ‘th’ interchange is possible but slightly less likely than the same interchange in Tamil. But far less likely in English. (‘tan’ and ‘than’ are pronounced completely differently)
Most of the magic lies in the design of these edit penalties. For highest precision and recall we have crafted edit penalties for Hindi and a few more Indian languages manually. These penalties are decided from a detailed analysis of the typical phonetic errors users made as seen from user queries and keeping in mind intended searched content.
As we expand to other languages, edit penalties can also be learnt through a language model of user queries and their corresponding click and navigational behavior after the search. This reduces the dependency on language expertise and manual handcrafting of phonetic rules.
Using the Indi-Editex metric we cluster together all tokens which are phonetically similar to each other within a given language. Our universe of tokens comes from the vocabulary we see in our song titles, user queries and lyrics. Tokens from queries don’t come with language information but an analysis of subsequent clicks behavior gives us some hint into the intended language.
We now expand our index to include not just the original token but also all of its phonetic variations.
Thus, a query for both ‘dilwaale’ (double ‘a’) and ‘dilvale’ (‘v’ instead of ‘w’) would result in finding ‘Dilwale’ (meaning ‘big hearted’)
How The Pieces Fit Together
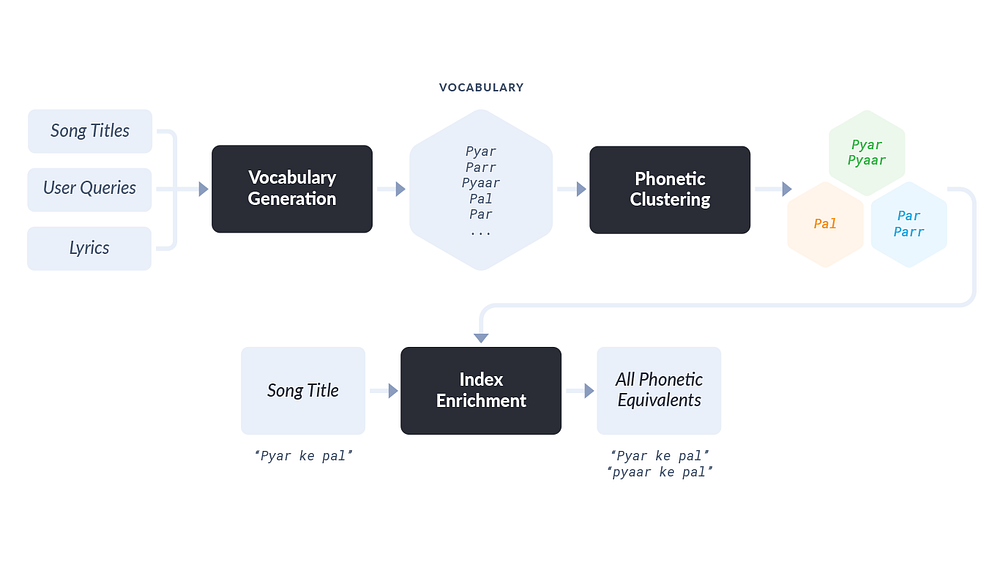
Phonetics Framework Architecture
Moving from design to implementation, we break our phonetics framework into two components.
- First, generating and updating a vocabulary of tokens and all their phonetic equivalents.
- Second, using this vocabulary to enrich our search index to support phonetic match in queries.
The first component in our framework is phonetics enriched vocabulary generation which works as follows:
- Everyday we update our universe of tokens in every language using three key sources:
- Song titles from our ever growing catalogue, we have the knowledge of language here.
- User queries. Since we can’t classify language very easily here we use an analysis of click behavior after a query to guess language.
- Lyrics and other data that comes along with songs.
- We run a distributed processing script using Apache Spark to process this large vocabulary and identify phonetic equivalent tokens. The goal of the script is to cluster groups of tokens with low Indi-Editex scores. All tokens within a cluster are phonetically equivalent.
- We store this phonetics enriched vocabulary in a format usable by our index.
The second component of our phonetics framework is the index enrichment module which works as follows:
- Using the phonetics enriched vocabulary created by the vocabulary generation module, we enrich each token in our index with all its phonetic equivalent tokens. Thus, a search using any one of the many phonetic equivalents will make a particular song searchable.
- However, phonetic equivalents are not treated identical to the original song name. To avoid false positives due to phonetic matching as well as a sharp focus on exact matches in case of ambiguous queries, we always weigh the original song name higher than fuzzy matches of the same song name.
How Do We Compare With State-Of-The-Art ?
There exist a number of existing algorithms which tackle the problem of phonetics matching such as Soundex, Metaphone, Double Metaphone, etc. One such algorithm Beider-Morse is considered to be the current state of the art.
Most existing algorithms are tailored for English and European languages and their phonetic rules don’t work as well on Indian content. These algorithms reduce a word to a standard phonetic representation and use the phonetic representation to identify two phonetically similar words. The issue with these algorithms is that often too many words may have the same phonetic representation even though they may be fairly different in pronunciation.
A quick test on Hindi data revealed that the tokens ‘pyar’ (meaning ‘love’) and ‘par’(meaning ‘but’) would reduce to the same soundex code ‘P600’, thus yielding the algorithm too generic and unsuitable for our purpose.
Our phonetic matching approach using Indi-Editex outperforms Beider-Morse on a majority of queries. Beider morse which is considered the state of the art in phonetic matching algorithms is able to cover only an average of 62% of the variants we cover using Indi-Editex on Hindi.
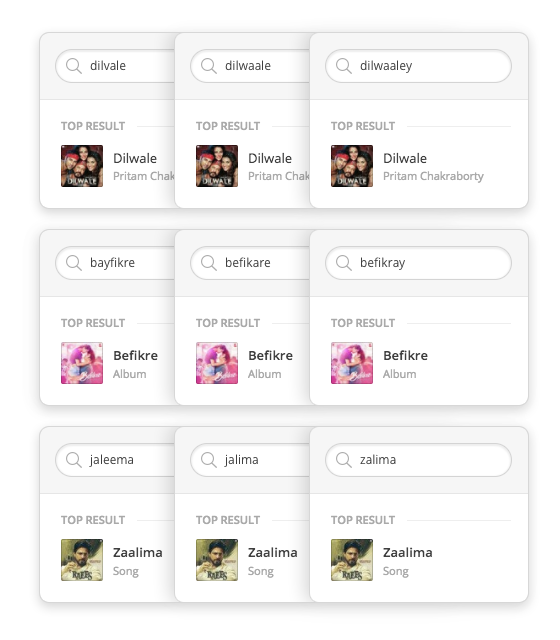
Phonetics in Action
On one of our most popular albums from Feb 2017 “Raees” (meaning ‘wealthy’) Beider-Morse could not cover variants such as ‘rayees’, ‘raes’, ‘rayes’, ‘raiees’
Similarly on another popular album “Dangal” Beider-Morse missed a highly probable variant ‘Dungal’ and on the popular album from 2016 “Dilwale” Beider-Morse misses the variant “Dilvale”
Phonetics In Action
Our phonetics framework has been powering Saavn search smoothly for over a year now and starting from Hindi we have expanded it to other major Indian languages such as Telugu and Punjabi.
It has helped us serve results for phonetically similar queries with ease and driven up our search relevance and subsequent search click rates considerably.
The issue of phonetics in Saavn search has been proof of how our use case and data (multilingual Indian content but all in English script) puts us in a unique place requiring the development of a tailor made solution to a complex problem, where no out of the box tool could serve our required purpose.
The development of phonetics at Saavn has been a great example of how exploring the depths of language, user behavior and engineering has resulted into creating an intuitive and fluid user experience.
And yes, we know some of you spell it ‘Saawan’; but our phonetics framework knows you actually mean ‘Saavn’.