
At Saavn, search is the entry point to 36 million songs across hundreds of languages. In fact, over a quarter of our streams start from a search. Our listeners search for music in unique ways apart from the obvious queries containing just song names, or artist names.
The other day a listener queried “old hindi songs of rajesh khanna”. We looked closely at this query and realized that the user was trying to give us the following pieces of information to explain his/her needs. Wanting to listen to songs by the artist ‘Rajesh Khanna’, these songs should only be in the ‘Hindi’ language and ‘old’ (a possible indication of the golden era of Hindi music).
Search at Saavn is implemented using Solr which creates an inverted index over all the searchable songs. When a query is made, Solr retrieves results containing query tokens in the song name, album name, artist name or other fields. These results are then ranked on the basis of the degree of overlap with the query, as well as popularity of the song.
How Solr Performs a Search — Token Matching
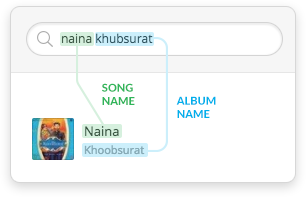
However Solr’s out-of-the-box token matching approach, is not sufficient to answer semantic queries.
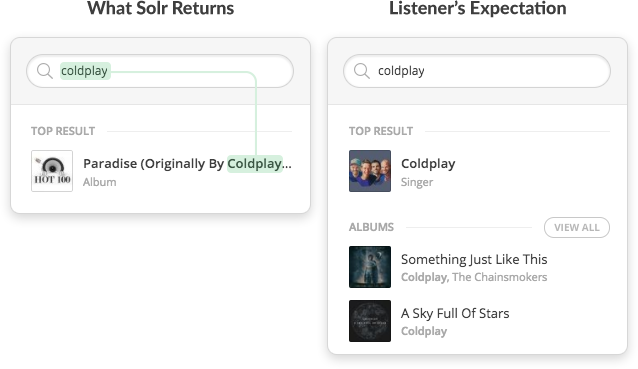
Where Solr’s token matching fails — Differentiating artists from song or albums
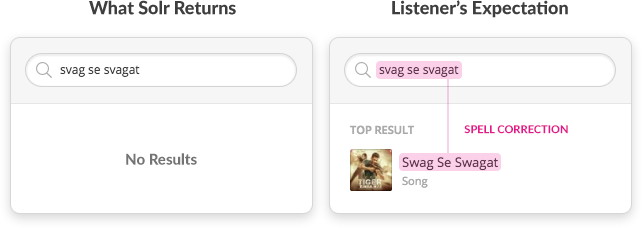
Where Solr’s token matching fails — Spell correction
Based on context it is important to preprocess a query, and identify insights such as which parts of the query represent artist names, year, genre etc. This helps us decide which token in a query to drop, which to spell correct, which to use as a filter and which to use directly for token matching.
To achieve this, we built an Entity Extraction layer. This layer preprocesses a search query before sending it to Solr, to add structure and meaning to it, using which we formulate better Solr queries and retrieve results with higher precision.
Defining the Entity Extraction Task
The goal of Entity Extraction is to convert a search query into a list of search entities.
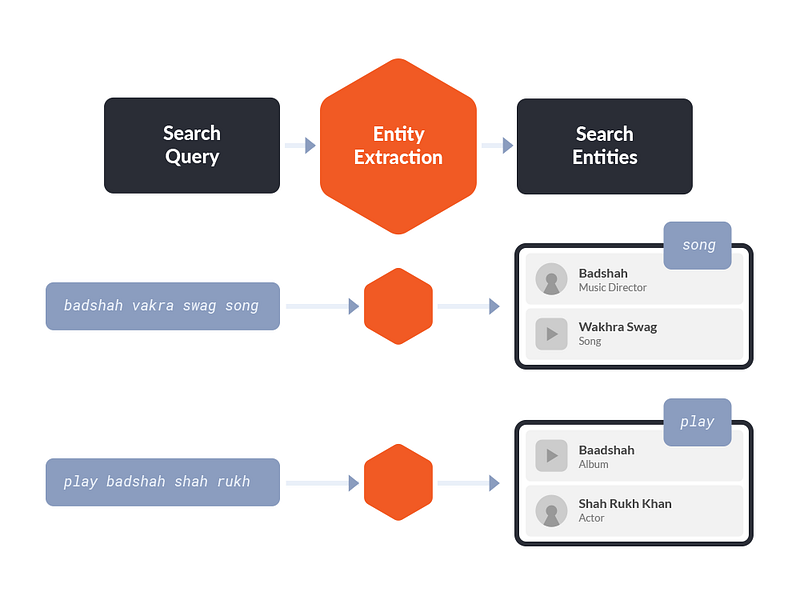
Entity Extraction From Search Queries
An entity is either a song, album, artist, mood-and-genre, language, or year.
A search query on Saavn is made up of one or more of these entities, and each entity in the query helps a listener to refine his search and converge towards desired results. Apart from this, a query can only contain semantic words such as ‘songs’, ‘play’, ‘hits’, ‘by’, ‘from’ etc. which do not add additional information but simply help form a coherent query.
A search query can contain a single entity e.g. “sholay”, “tere bina zindagi”, “hrithik roshan”, “2017 songs”, “hip hop” or it may contain two or more entities e.g. “arijit singh songs from 2016”, “naina from dangal”.
Designing A Solution
This is a classic entity extraction problem which we solve using a bottom-up approach. This involves two steps, candidate extraction and candidate scoring.
Step 1 : Candidate extraction.
Find all possible candidate entities for each span of one or more tokens. At this point we look at each span in isolation.
To achieve this, we need an Ontology.
Conceptually, an Ontology is a graph of all entities of the domain as well as their interconnections. In terms of implementation, it is a data store containing the features of each entity (such as name, id, type) as well as relationship between two entities (e.g. artist ‘arijit singh’ is singer of the song ‘raabta’).
The key requirement from an Ontology is that it must take a span of one or more tokens as an input and return a set of candidate entities as output. Since we are dealing with user typed search queries, the token or span may not be the exact spelling of an entity. Hence inexact or fuzzy search capabilities are desirable in an Ontology.
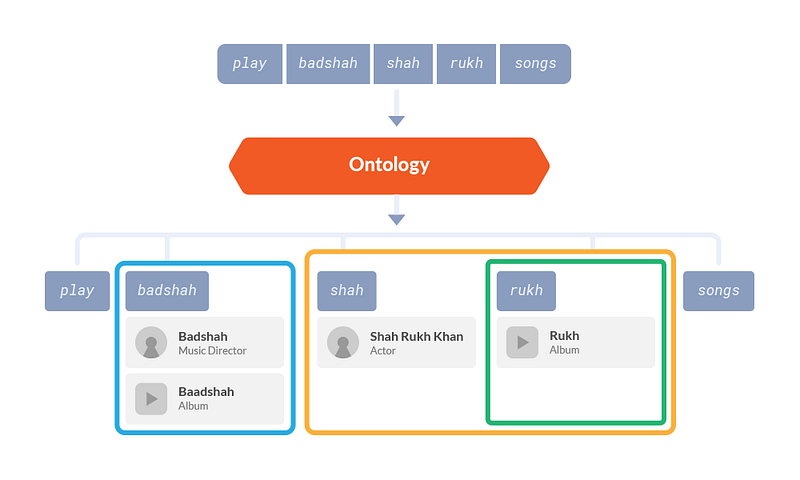
Step 1 : Candidate Extraction using Ontology
Step 2 : Candidate scoring.
Combine candidates for each span, score them, and arrive at a best set of entities for the entire query. Context plays an important role here.
For this step we require a Semantics Engine.
Semantics Engine is an encoding of the domain knowledge used to combine, score and choose between candidates for each token or span of a query to arrive at a final entity list. Since Saavn is a vertical search engine, a rule based semantics engine is effective in capturing the observable patterns in our search queries.
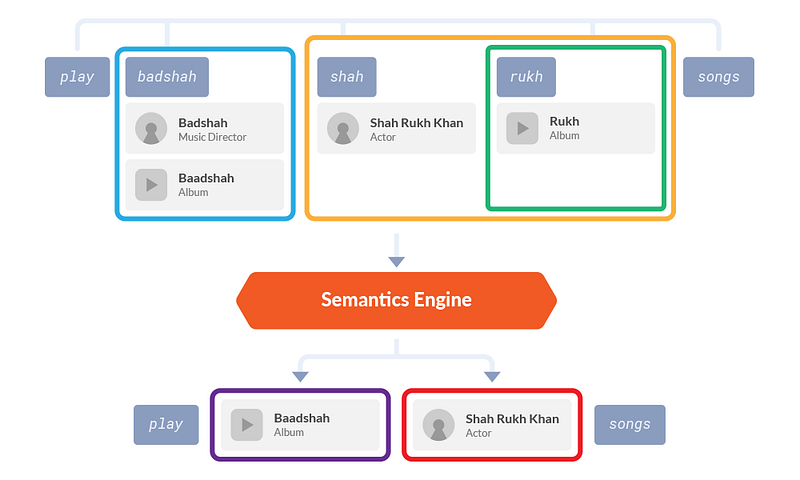
Step 2 : Candidate Scoring using Semantics Engine
Implementing the Entity Extraction Layer
Our design of the entity extraction layer consists of two steps viz. candidate extraction (using Ontology) and candidate scoring (using Semantics Engine). Let us now look at how we implemented these two steps.
Solr Ontology Data Store for Candidate Extraction
We use Solr as the primary data store for our ontology (+ an index of our entire music catalog. The Solr setup for the Ontology and for the actual search index are separate). We create a Solr document for each entity in the Saavn domain and index it onto the Ontology collection. We query the collection with a span of one or more tokens, and it returns all candidate entities possible for that span.
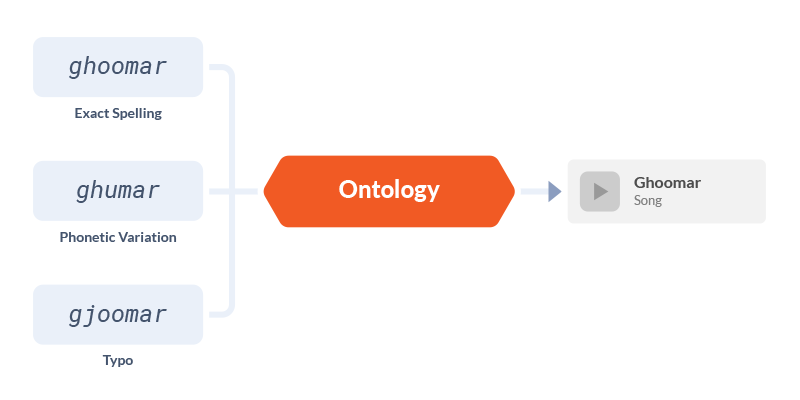
Ontology allows fuzzy matching, and spell correction support
We chose Solr for this purpose instead of a NoSQL database such as Mongo because an Ontology must support more than direct lookup. Solr allows us to index many variations (typos, sounds-like phonetic variations, abbreviations, alternate names) of the same entity name, thus allowing better entity recalls. Since spans come from a listener’s search query and can be ill-formed or misspelt; this capability of Solr is useful. This way, the ontology also helps us in spell-corrections.
The Ontology collection on Solr is dynamic. As new content is added to our catalog and songs and albums pick up and lose popularity, a pipeline keeps the collection updated to reflect the set of entities expected in queries based on current trends of music.
Semantics Engine for Candidate Scoring
We’ve written our custom Semantics Engine to perform candidate selection using a rule based approach which is powered by Saavn’s domain specific intelligence.
An example of Saavn’s domain specific intelligence, enforced by the Semantics Engine, is that a listener will not search for two song names in a single search query. Thus, for a single query the entity extraction layer will not predict two song names one after another as entities. Similarly, an album name and artist name will co-occur in a query only if the artist plays a role (singer, actor, director etc) in the album.
To give another example, in the query ‘play badshah shah rukh songs’ the Semantics Engine realizes that from all the candidates, artist ‘Shah Rukh Khan’ and the album ‘Baadshah’ make the most sense together because Shah Rukh is an actor in the movie Baadshah.
Similarly, for the query “shaan” the semantics engine picks the more popular entity which is the artist named “Shaan” whereas for the query “shaan movie” the semantics engine prefers an album instead because of the cue from the keyword ‘movie’.
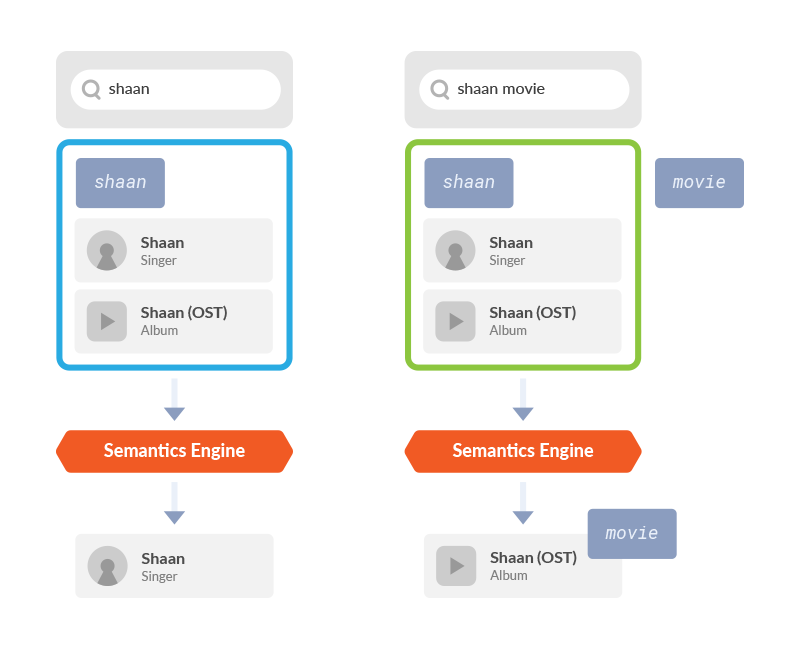
Semantics Engine uses cues in the query to pick best set of candidate entities
Building an Offline Entity Extractor for Frequent Queries
Offline entity extractor is a daily batch process which utilizes a combination of Saavn’s query logs and external data sources to build machine learning models to extract entities for high volume queries with higher accuracy.
The entity extraction layer we discussed so far was an online process executed during query-time. However, we realize that all this computationally intensive processing is not required repeatedly for frequent queries. Hence, the offline entity extractor pre-computes entities for frequent queries whereas the online entity extractor handles new and unseen queries.
These precomputed entities are stored in an Entity Cache.
In fact entity extraction for 70% of the queries in a day is done through the entity cache, with only the remaining 30% being served through the online entity extraction component.
Putting it all Together
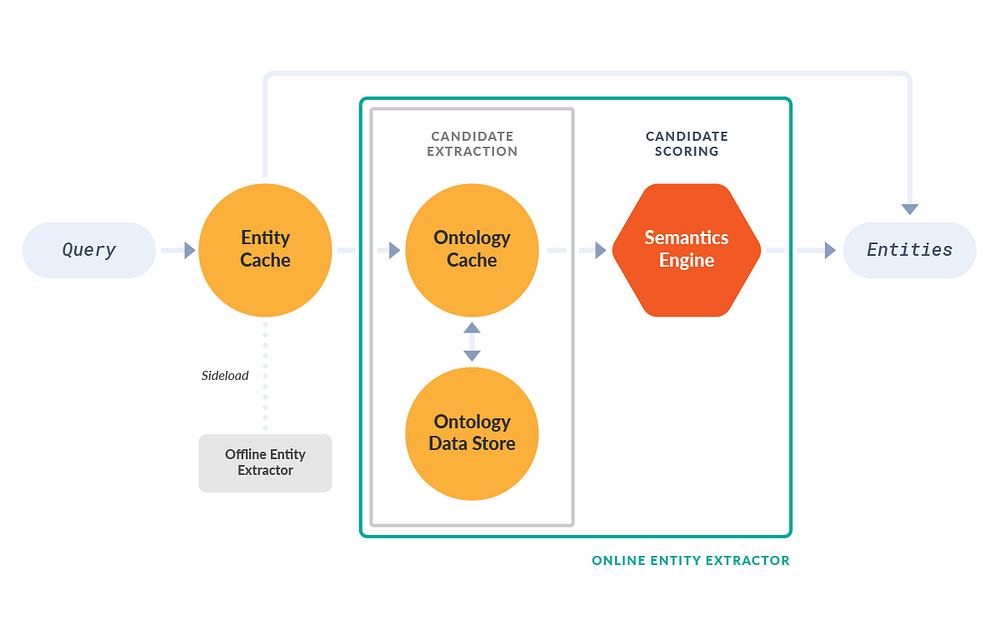
Entity Extraction Architecture
- Every time we receive a query we first look it up in our Entity Cache. If entities for the query are found in cache, they are sent to the Search API directly.
- If the query is not found in the Entity Cache, we break it up into spans of one or more tokens.
- Each span is looked up in the Ontology Data Store to generate candidate entities. The ontology data store has an Ontology Cache for faster lookups.
- We then send our candidates to the Semantics Engine which scores and selects the final list of entities.
- The final entities are sent to the Search API.
- The search API formulates semantic queries using the search entities, which are then sent to our primary Solr search index.
Impact of Entity Extraction
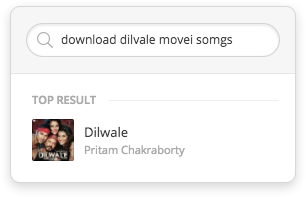
Saavn’s Entity Extraction in Action
Improved Relevance
Our entity extraction layer helped us achieve an 8–10% increase in search click rates on long length queries. This contributed to an overall jump of 2% in our search click rates.
Faster Search
Entity extraction allows us to perform efficient Solr queries due to the knowledge of the semantics of the query. This may be due to the addition of filters to the query, restricting the search to a subset of fields and other optimizations. This allows us to maintain an average Solr response time of 20ms ensuring that we continue to keep our promise of being the fastest music app.
Better Query Classification
Entity extraction also allows us to identify query categories such as whether a query is navigational i.e. pointing to a single piece of music (e.g. “gerua from dilwale” pointing to a single song) or exploratory i.e. pointing to a broad class of similar music (e.g. “marathi hits” pointing to all songs of a language).
Better classification allows us to customize the search UX by reordering the search facets and surfacing song and albums for navigational queries and relevant playlists, radio stations, channels and artists for exploratory queries.
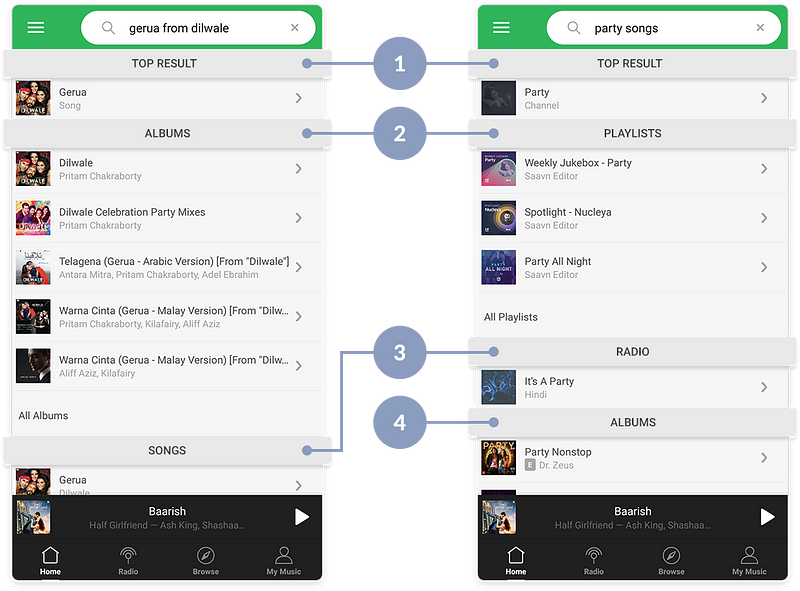
Albums and Songs for Navigational Queries, Channels, Playlists, Radio for Exploratory Queries
Conclusion
We built an entity extraction layer to preprocess search queries and use the semantics extracted from queries to improve the search experience.
To achieve this we created an Ontology Data Store using Solr which we use for extracting candidate entities for spans within the query. We then use the Semantics Engine to score candidates and select the optimum set of entities for a query. The entities found can be used to formulate better search queries which return both relevant search results as well as reduce search response time. We also see how we can make this layer efficient to support production volumes by delegating processing for frequent queries to an offline entity extractor and the use of caching.
On the whole, entity extraction has allowed us to better understand a listener’s intent and shorten the journey to their favorite music.
Illustrations by Fahm Sikder